

はじめに
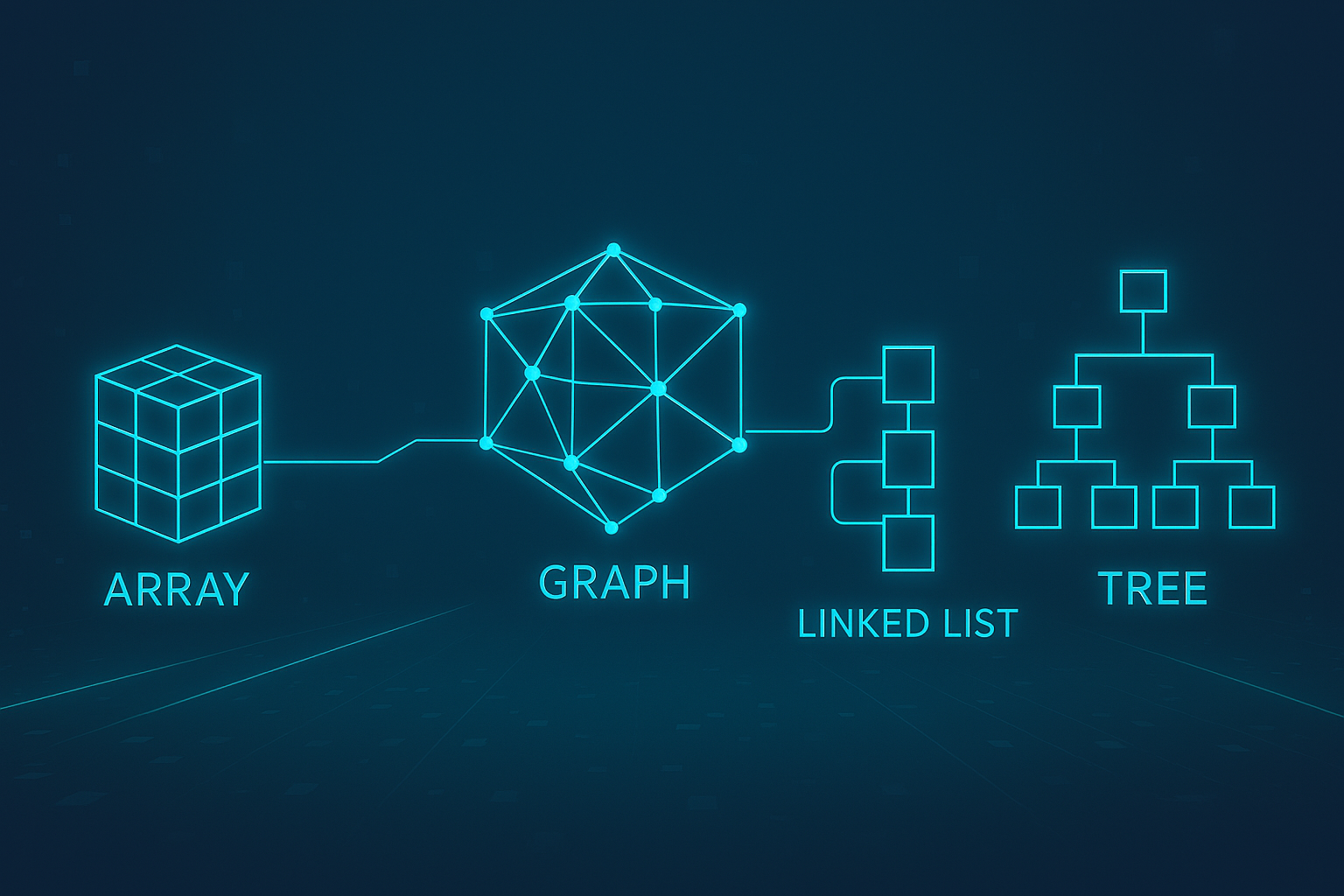
基本情報技術者試験では、アルゴリズム問題の基盤として「データ構造」が必ず登場します。データ構造とは、コンピュータが情報を効率的に管理・処理するための仕組みであり、試験ではスタックやキュー、リスト、木構造、グラフなどの基本的な構造が問われます。これらを理解していないと、擬似言語を使ったアルゴリズム問題を解くことが難しくなるため、合格のためには避けて通れない分野です。
 オルビナ/基本情報技術者専門官
オルビナ/基本情報技術者専門官では、なぜデータ構造が必要なのでしょうか。コンピュータは膨大なデータを扱う際に、ただ記憶するだけではなく「効率的に取り出せるように並べ方を工夫」しています。こうした仕組みを作ることで、情報を忘れることなく整理し、必要なときにすぐ取り出せるのです。例えばストレージのファイル管理や、キャッシュによる高速アクセスなども、データ構造の考え方が活躍している代表例です。
代表的なデータ構造と特徴
スタック
まず「スタック」は、後から入れたデータを先に取り出す「後入れ先出し(LIFO)」の仕組みを持ちます。イメージとしては、積み重ねたお皿の山から一番上のお皿を取るようなものです。プログラムの世界では、関数の呼び出し履歴を管理する「呼び出しスタック」や、テキストエディタの「Undo(元に戻す)」機能などで使われています。試験問題では、スタックに数値をプッシュ(追加)してポップ(取り出す)処理を追う問題がよく出題されます。
オルビナ/基本情報技術者専門官スタックは「後入れ先出し(LIFO)」の仕組みを持ち、最後に入れたデータを先に取り出します。一見すると「最初に入れたものがすぐに取り出せないので意味がない」と思うかもしれませんが、実際には関数の呼び出しやUndo機能など、直前の操作を優先的に処理する場面で大きな役割を果たしています。
キュー
次に「キュー」は、先に入れたデータを先に取り出す「先入れ先出し(FIFO)」の仕組みです。これはスーパーのレジ待ちの行列をイメージすると分かりやすいでしょう。最初に並んだ人が最初に処理され、最後に並んだ人は最後に処理されます。コンピュータでは、プリンタの印刷ジョブ管理や、ネットワーク通信のパケット処理などに利用されます。試験では「キューにデータを順番に入れて、取り出すとどうなるか」を問う問題が頻出です。
オルビナ/基本情報技術者専門官身近な例として「ブラウザの履歴」もイメージに近い部分があります。検索すると新しい履歴が追加され、古い履歴は次第に後ろへ押し出されていきます。
完全なキュー構造ではありませんが、「新しいものが追加され、古いものが自然に消えていく」という点ではキュー的な性質を持っていると言えるでしょう。
配列
配列とは、同じ種類のデータをひとまとまりにして、連続した領域に格納する仕組みです。例えば「10人分の点数」を管理したいとき、配列を使えば score[0] から score[9] までのように番号(インデックス)を付けて扱うことができます。これにより、必要なデータを瞬時に取り出すことができ、処理の効率が大幅に向上します。
オルビナ/基本情報技術者専門官配列を使うことで、データを連続して管理できるため高速アクセスが可能になり、同じ種類のデータをまとめて扱えるため整理も容易になります。さらに、探索や整列といったアルゴリズムの基盤として必ず登場するため、基本情報技術者試験でも重要な役割を果たします。ただし、サイズを途中で変更したり要素を削除したりするのは苦手なので、その点も理解しておくとより実践的です。
連結リスト
「連結リスト」は、ノード(点)と呼ばれる要素をポインタでつなぐ構造です。配列と違い、要素を追加・削除する際に全体を動かす必要がなく、柔軟に操作できます。例えば、音楽プレイヤーのプレイリストで曲を追加・削除するような場面に適しています。試験では「ノードを追加するとポインタのつながりがどう変化するか」を図で追わせる問題が出題されます。
オルビナ/基本情報技術者専門官実際のコンピュータの世界でも、連結リスト的な仕組みは活躍しています。例えばファイルシステムでは、ファイルを保存するときにデータを複数の領域に分けて管理し、それらをポインタでつなぐことで効率的に扱っています。つまり「ファイルを消したり追加したりする処理の裏側」には、連結リストの考え方が応用されているのです。
木構造
「木構造」は、階層的なデータを表現するのに適した構造です。例えば、パソコンのフォルダ階層や会社の組織図が木構造の典型例です。特に「二分探索木」は、左の枝には小さい値、右の枝には大きい値を配置するルールを持ち、効率的な探索を可能にします。これにより、データを探す際に全体を順番に調べる必要がなく、探索時間を短縮できます。試験では「二分探索木に値を挿入するとどこに配置されるか」を問う問題がよく出ます。
オルビナ/基本情報技術者専門官分かりやすく言えば、大きな会社がいくつかの子会社を持ち、その子会社がさらに複数の工場を持っている、といった構造です。上位の組織から下位の組織へと枝分かれしていくことで、下に進むほど情報がより詳細になっていきます。これがまさに木構造の特徴であり、階層的な関係を整理して表現するのに適しているのです。
グラフ
最後に「グラフ」は、ノード(頂点)と辺(つながり)で構成される複雑な関係性を表現できる構造です。道路地図やSNSの友達関係などが典型的な例です。試験では、グラフ探索アルゴリズムとして「深さ優先探索(DFS)」と「幅優先探索(BFS)」がよく問われます。DFSは一つの道をできるだけ深く進んでから戻る方法、BFSは近いノードから順番に広がっていく方法です。これらはネットワーク経路探索や迷路問題の解法に応用されます。
オルビナ/基本情報技術者専門官分かりやすく言えば、各駅を「頂点」、駅を結ぶ路線を「辺」と考えるとイメージしやすいでしょう。さらに、辺に「所要時間」や「距離」といった重みを設定すれば、最短経路の計算も可能になります。例えば東京から大阪までを考えると、頂点は東京と大阪、辺はその間を結ぶ新幹線の線路です。このようにグラフ構造を使えば、複雑な経路や関係性を整理して効率的に計算できるのです。
出題傾向と対策
基本情報技術者試験では、擬似コードや図を使って「この処理はスタックかキューか」「この探索はどの順序で進むか」といった問題が出題されます。スタックとキューの違いを問う基本問題は頻出であり、木構造やグラフ探索は応用的な問題として出題されやすい傾向があります。
対策としては、過去問を繰り返し解き、処理の流れを図解しながら理解することが効果的です。特にアルゴリズム問題は「手を動かして追う」ことで理解が深まるため、紙に書いてシミュレーションする学習法が有効です。











コメント