

結論は?
 詠架/AI副参事
詠架/AI副参事・データが少なくても一番似てるヤツを近づく手法
・大量データは不要
つまり?
詠架/AI副参事人間の学習仕方にめっちゃ似てる!
はじめに
おいおい、「プロトタイピカルネットワーク」って知ってるかい?聞いてるだけで、なんか「プロトタイプのネットワーク」みたいな、SF映画に出てくるロボットの脳みそみたいじゃん。でも安心しろよ、実はめっちゃシンプルで、人間が新しいものを覚える仕組みに似てるんだ。データがクソ少ない状況でAIが賢く分類してくれる魔法みたいな手法だぜ。
ふざけんなよ、普通のAIはデータ山ほど食わせないと動かないのに、これなら数個の例で「はい、わかりました!」ってなるんだから、ズルいよな。
プロトタイピカルネットワークとは? 基本の意味をバカみたいに簡単に解説
詠架/AI副参事プロトタイピカルネットワークは、2017年にJake Snellらによって提案されたAI手法。主にfew-shot learningで使われているよ。
- few-shot learningって何? 普通の機械学習は、数千・数万のデータで訓練するけど、few-shotは「1個~5個くらいの例だけ」で新しいクラスを認識させるんだ。例: 子供が猫の写真2-3枚見て「これ猫!」って覚えるみたいに、AIも少量で一般化する。
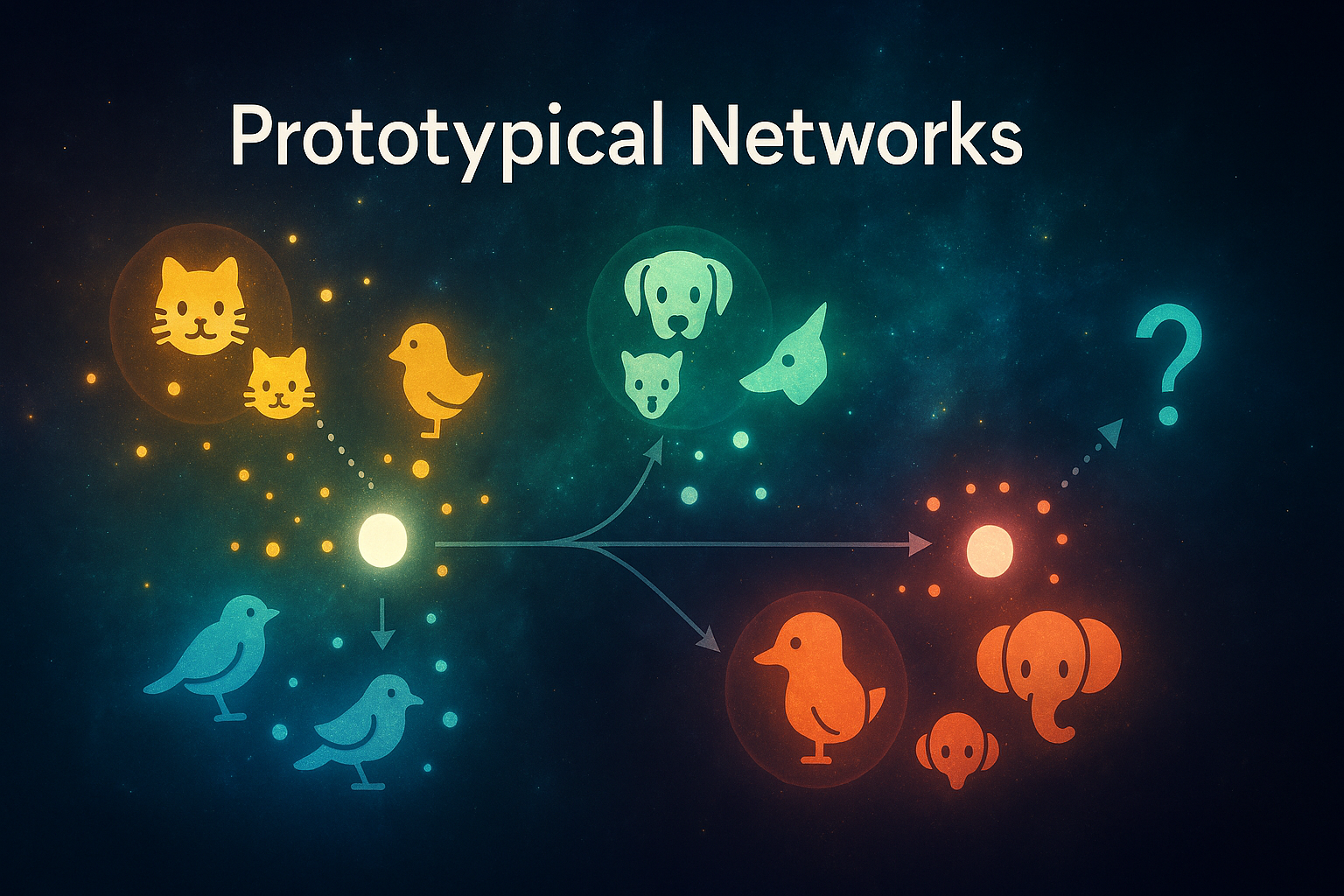
プロトタイピカルネットワークの核心は:、各クラスを「プロトタイプ」(代表点、つまり平均みたいなヤツ)で表現して、距離を測って分類する。
つまり、データ少ないのに「このクラスはこんな感じの中心点があるはず!」って仮定して、クエリ(新しいデータ)をその中心に一番近いクラスに割り当てる。シンプルすぎて笑えるだろ? でもこれが強いんだよ。
なんでこんな手法が生まれた?
詠架/AI副参事AIの深層学習はデータ食いモンスターだよ。
ImageNetみたいに何百万枚ないとまともに動かない。でも現実世界は珍しい病気の医療画像とか、希少動物の写真とか、データ集められないことが多い。
そこでmeta-learning(学習を学習する)が出てきて、few-shot learningが熱くなった。プロトタイピカルネットワークは、その中でmetric-based(距離ベース)の代表格。Matching Networksとかよりシンプルで、性能もいいから人気爆発したんだ。
論文(arXiv:1703.05175)では、miniImageNetやOmniglotでSOTA(当時最高性能)叩き出してるよ。複雑なmeta-learningより「平均取って距離測るだけ」で勝っちゃうんだから、AI研究者涙目だろ。
仕組みを詳しく分解! ステップバイステップで分かりやすく
詠架/AI副参事プロトタイピカルネットワークの流れはこうだぜ。エピソードトレーニング(毎回ランダムにタスク作って訓練)で学ぶのがポイント。
- Embedding関数(ニューラルネットワーク)で特徴抽出 CNNとかのニューラルネットで、入力(画像とか)を低次元ベクトル(embedding)に変換。同じクラスのものは近くに、違うのは遠くに集まる空間を作る。
- サポートセットからプロトタイプ計算 N-way K-shotタスク(Nクラス、K例ずつ)で、 各クラスのプロトタイプ c_k = (1/K) * Σ f_φ(x_i) つまり、サポート例のembeddingの平均! 要は平均をとるだけ。バカシンプルだろ?
- クエリ分類 クエリxのembeddingと各プロトタイプの距離d(普通はユークリッド距離)計算。 確率: p(y=k|x) = softmax(-d(f_φ(x), c_k)) 一番距離近い(負の距離でsoftmax)のが予測クラス。要は近ければ近いほど、そのクラスである確率が高い!ってことです。
- 損失関数 クロスエントロピーとかで、クエリが正しいクラスに近づくように訓練。
- zero-shot拡張も可能 クラス名や属性からプロトタイプ作って、例ゼロでも分類。鳥のデータセットでSOTA出してるよ。
訓練時はたくさんエピソード繰り返して、「少量データで適応する」能力をmeta-learnするんだよ。
他の手法と比べてどう? 優位点と弱点、比較
- vs Matching Networks:Matchingは全サポート例とクエリを個別に比較(attention使う)。ProtoNetsは平均プロトタイプ1つだけだから、計算軽くてスケールいい。性能もProtoNetsのが上多い。
- vs Relation Networks:Relationは関係学習するけど複雑。ProtoNetsは「距離だけ」でシンプル勝ち。
- vs MAML(Model-Agnostic Meta-Learning):MAMLはパラメータ更新で適応するけど、重い。ProtoNetsは非パラメトリック(プロトタイプ計算だけ)で速い。
メリット
- シンプルで実装しやすい(PyTorchコードいっぱいあるぜ)
- データ少ないのに頑健
- 距離メトリック変えれば柔軟(定規の種類を持ち替えるだけで、どんなクセのあるデータにも対応できるぜ)
デメリット
- クラス内変動大きいと平均プロトタイプがヘタレになる(例: 犬の品種多すぎ)
- 埋め込み空間の質に依存しまくり(地図がデタラメだったら、いくら最短距離を測っても目的地には着けないだろ?)
でも全体的に、few-shotのベースラインとして今でも使われてるよ。ふざけんな、2017年の手法がまだ現役って強すぎだろ。
実際の応用例と未来
医療画像診断(珍しい病気)、薬発見、顔認識(プライバシーでデータ少ない)、ロボット学習とかで活躍。変種もいっぱい:Attention入れたり、Transductive(クエリも使う)バージョンとか。
これで君もProtoNetsマスターだぜ。データ少ないのに賢くなるAI、羨ましいよなー。もっと知りたきゃ論文読めよ。








コメント