

結論は?
 詠架/AI副参事
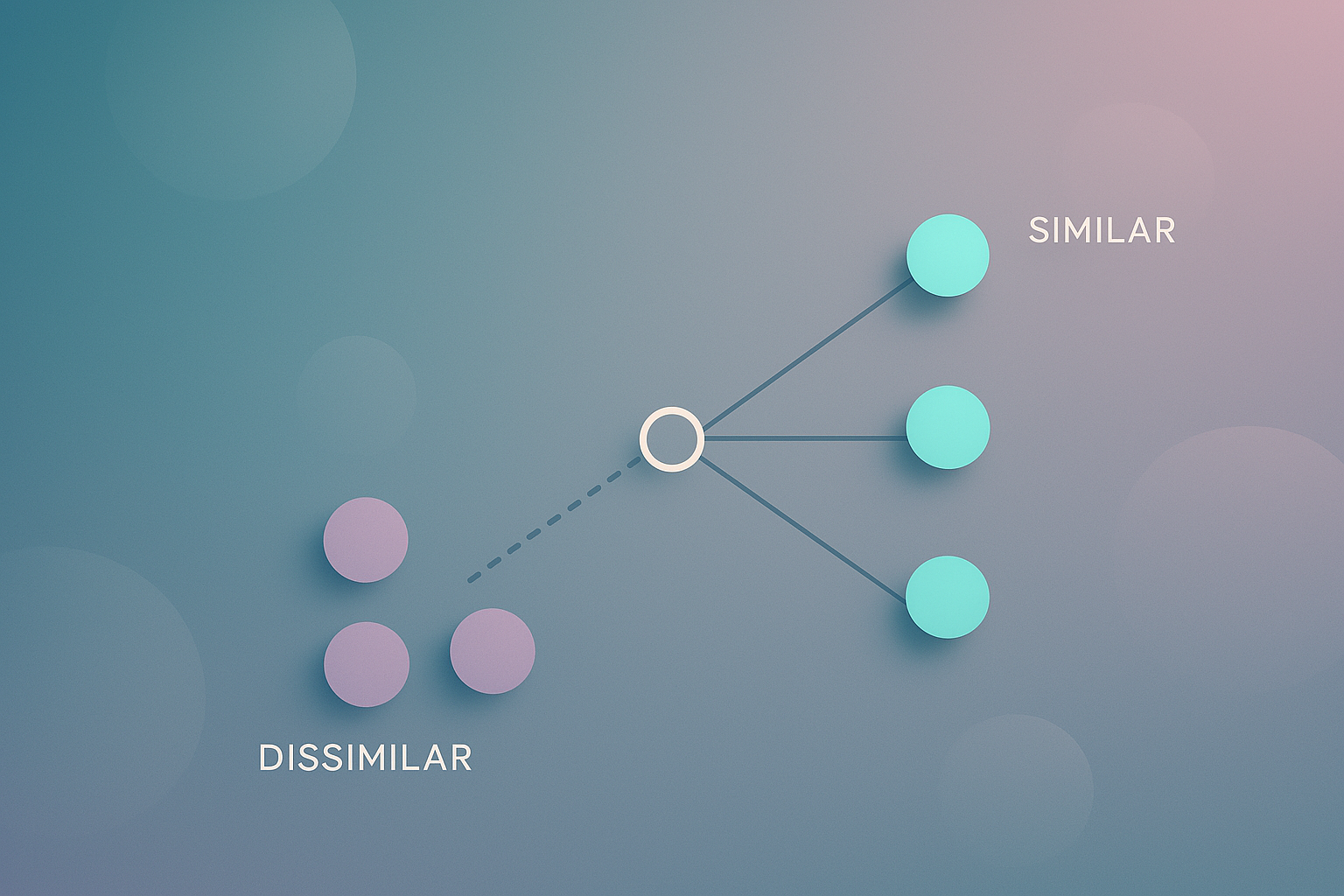
詠架/AI副参事・似てるなと思ったら元の画像のそばに似てる画像を置くという考え方だよ
・似てないと思ったら元の画像から離れて似てない画像を置く
・顔認識がよく使われてる
つまり?
詠架/AI副参事顔認証で本人確認することで、スマホのロック解除や入退室管理に使われてるよ
はじめに
おいおい、metric-basedって聞くと「メートル法ベース?」とか思う奴いる? 違うよバカ!(笑) 今日は「metric-based」について、ガッツリ詳しく解説するぞ。
metric-basedの基本的な意味
詠架/AI副参事metric-basedとは 「距離(metric)を中心に考えるアプローチ」のことだよ。
機械学習、特にメトリックラーニング(Metric Learning)やメタラーニングの分野で使われる。 データポイント同士の「似てる度合い」を、数値的な距離(distance)で測って、それを学習で最適化する手法の総称だと思えばOK。
- metric = 距離関数(例: ユークリッド距離、マンハッタン距離、マハラノビス距離など)
- based = その距離をベースに判断する
つまり、「似てるものは近く、似てないものは遠くに配置する地図を自動で作る」みたいなイメージ。 顔認識とか商品推薦とかで「こいつら似てるな」を自動で判定するのに超便利。
なんでmetric-basedが大事なの?
普通の分類器(SVMとかNNとか)は「ラベルを見て境界線引く」みたいな感じだけど、 metric-basedは「ラベルなくても、距離だけで似てるグループを作れる」のが強み。
特に少量データで威力を発揮する。
データが10件しかなくても、「この5枚の猫の写真の平均位置をプロトタイプにして、新しい写真が近いかどうか判定」みたいな芸当ができる。
metric-basedの代表的な手法
| 手法 | 学習・判定の考え方 | メリット(強み) | デメリット(弱点) |
| Prototypical Networks | クラスの「平均(重心)」を算出して、一番近い所に分類する。 | 実装が極めてシンプルで計算も軽い。少ないデータでも驚異的に動く。 | クラス内のバラツキが激しいと、平均では代表しきれない。 |
| Relation Networks | 「関係性判定AI」を使い、2つのデータが似ているかスコア化する。 | どこに注目すべきかAIが自動学習する。複雑なデータに対し、単純な距離計算より柔軟。 | 判定用ネットワークが必要な分、計算量が増える。構造が複雑で学習が不安定なことも。 |
| Matching Networks | 「注意機構」を使い、個別のデータと比較・投票する。 | 「平均」に集約しないため、クラス内に見た目が違うものが混ざっていても対応可能。 | サポートセットが増えると計算量が増大する。個別のノイズに弱い。 |
| Siamese / Triplet | 「ペア/3つ組」で、似てるものは近く、違うものは遠くへ配置する。 | 顔認証等で実績多数。未知のクラス追加に強く、微細な差を見抜く力が高い。 | 「ちょうどいい難問」を選ぶサンプリングが地獄。学習が「崩壊」しやすい。 |
| マハラノビス 距離学習 | 「データの分布」を考慮して、距離空間を伸縮させる。 | データの相関を考慮できる。統計的な裏付けが強く、分布が歪んでいても正しく測れる。 | 事前に共分散行列を求める必要があり、データが極端に少ないと計算が不安定になる。 |
metric-based vs optimization-based(メタラーニングでの対比)
詠架/AI副参事メタラーニングではよく比較されるんよ
- metric-based(今回のお題) → 距離計算で素早く分類。計算が軽い。少量データに強い。
- optimization-based(例: MAML) → モデルパラメータを数ステップで微調整して適応。柔軟だけど計算重い。
「データ少ないならmetric-based、柔軟性が欲しいならoptimization-based」って覚えとけ。
実際の応用例(実用的なやつ)
- 顔認識(iPhoneのFace IDの裏側技術の一部)
- 商品推薦(Amazonの「これ似てる商品」)
- 医療画像診断(珍しい病気のfew-shot検出)
- ゼロショット学習の基盤技術
メリットとデメリット(正直に言うぞ)
メリット
- 計算が速い(特に推論時)
- 少量データで強い
- 解釈しやすい(距離見れば似てる理由が分かる)
デメリット
- 複雑な関係性は苦手(距離だけじゃ表現しきれない場合あり)
- ハイパーパラメータ(距離関数の選択)が面倒
- 大規模データだと他の手法に負けることも
まとめ:metric-basedって結局何?
「データ同士の距離を賢く学習して、似てるものを自動でグルーピングするアプローチ」 これだけで9割理解したことになる。残りの1割は実際にコード書いて遊べば分かるよ(笑)








コメント