

はじめに — アルゴリズムって何?
 幽灯子/基本情報技術者副専門官
幽灯子/基本情報技術者副専門官「アルゴリズム」と聞くと難しそうに感じるかもしれませんが、実はとてもシンプルな考え方です。アルゴリズムとは、ある問題を解くための手順・やり方のこと。
たとえば「カレーの作り方」もアルゴリズムの一種です。材料を切る → 炒める → 水を入れる → ルーを入れる、という手順を決められた順番で実行すれば、誰でもカレーが作れますよね。コンピュータの世界でも同じように、「データをどういう手順で処理するか」を決めたものがアルゴリズムです。
基本情報技術者試験(通称FE)では、このアルゴリズムの理解が非常に重要で、午後試験では必須の出題分野になっています。この記事では、試験で問われるアルゴリズムの基本を、身近な例を使いながらやさしく解説します。
1. アルゴリズムの3つの基本構造
 幽灯子/基本情報技術者副専門官
幽灯子/基本情報技術者副専門官すべてのアルゴリズムは、たった 3つの構造 の組み合わせでできています。これはプログラムの土台でもあるので、まずここを押さえましょう。
(1)順次(じゅんじ)— 上から順番に実行する
最もシンプルな構造です。書かれた命令を上から下へ、1つずつ順番に実行します。
身近な例: 朝の支度
起きる → 顔を洗う → 着替える → 朝ごはんを食べる → 家を出る
特に条件分岐もなく、ただ順番通りに進むだけ。これが「順次構造」です。
(2)選択(分岐)— 条件によって処理を変える
「もし〇〇なら△△する、そうでなければ□□する」というように、条件に応じて別の処理に分かれる構造です。プログラミングでは if文 に相当します。
身近な例: 天気と傘
もし雨が降っていたら → 傘を持っていく
そうでなければ → 傘を持たずに出かける
(3)繰り返し(ループ)— 条件を満たすまで同じ処理を続ける
同じ処理を何度も繰り返す構造です。プログラミングでは for文 や while文 に相当します。
身近な例: 手を洗う
石けんで手をこすり合わせる → まだ泡がついている? → はい → もう一度すすぐ → まだ泡がついている? → いいえ → 終わり
この3つを組み合わせるだけで、どんなに複雑なアルゴリズムも表現できます。
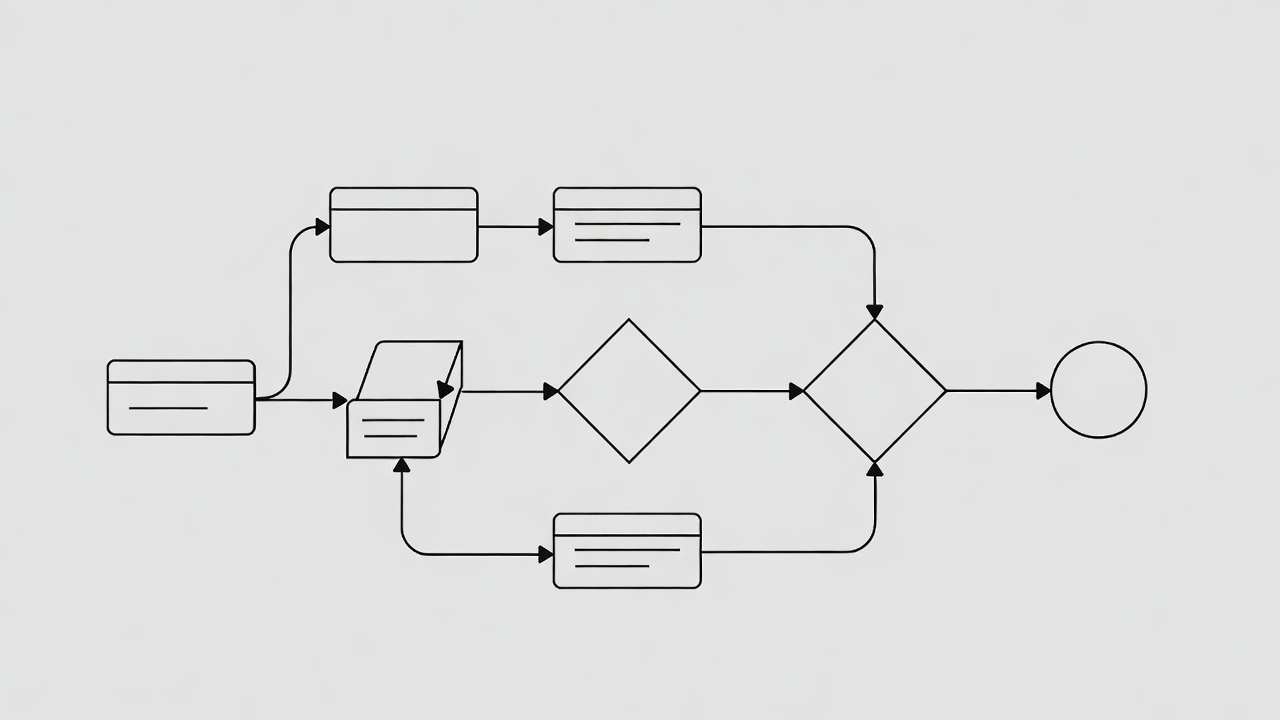
2. フローチャートを読めるようになろう
幽灯子/基本情報技術者副専門官基本情報技術者試験では、アルゴリズムがフローチャート(流れ図)で出題されることがあります。フローチャートとは、処理の流れを図で表したもので、使われる記号にはそれぞれ意味があります。
| 記号の形 | 意味 | 説明 |
|---|---|---|
| 角丸の四角 | 開始・終了 | 処理の始まりと終わりを示す |
| 四角 | 処理 | 計算や代入など、具体的な作業を行う |
| ひし形 | 判断(分岐) | 条件を判断して、YesかNoで分かれる |
| 矢印 | 流れ | 処理が進む方向を示す |
フローチャートを見るときのコツは、矢印を指でなぞりながら、1つずつ処理を追いかける ことです。最初はゆっくりで構いません。慣れてくると、パッと見ただけで処理の流れが把握できるようになります。
3. 試験で問われる代表的なアルゴリズム

3-1. 探索アルゴリズム — データの中から目的のものを探す
線形探索(リニアサーチ)
データを先頭から1つずつ順番に確認していく方法です。
身近な例: 本棚から特定の本を探すとき、左端から1冊ずつタイトルを確認していくイメージです。
シンプルですが、データが多いと時間がかかるのが欠点です。
二分探索(バイナリサーチ)
あらかじめ並び替え(ソート)されたデータに対して、真ん中の値と比較しながら探索範囲を半分ずつ絞り込んでいく方法です。
身近な例: 辞書で単語を引くとき、真ん中あたりを開いて「探している単語はもっと前?後ろ?」と絞り込んでいく要領です。
線形探索より圧倒的に速いですが、データが事前にソートされている必要があります。
3-2. 整列アルゴリズム(ソート)— データを並び替える
バブルソート
隣り合う2つのデータを比較し、順番が逆なら交換する、という作業を繰り返して全体を並び替えます。
身近な例: 背の順で並ぶとき、隣の人と背を比べて、自分の方が高ければ後ろに回る。これを全員が何度も繰り返すと、最終的にきれいな背の順になります。
理解しやすいアルゴリズムですが、データ量が多いと非常に遅くなります。
選択ソート
データの中から最小値(または最大値)を見つけて先頭に置く、という作業を繰り返す方法です。
身近な例: トランプの手札を小さい順に並べるとき、一番小さいカードを探して左端に置き、次に小さいカードを探して左から2番目に置き…と繰り返すイメージです。
挿入ソート
データを1つずつ取り出し、すでに並んでいる部分の正しい位置に挿入していく方法です。
身近な例: トランプで、1枚ずつカードを引いて手札の正しい位置に差し込んでいく感覚です。
3-3. 再帰(さいき)— 自分自身を呼び出す処理
再帰とは、ある処理の中で自分自身をもう一度呼び出すテクニックです。少し不思議に感じるかもしれませんが、実は日常にもヒントがあります。
身近な例: 合わせ鏡
鏡の中に鏡が映り、その中にまた鏡が映り…という「入れ子」状態。ただし、プログラムでは無限に繰り返さないように「ここで止まる」という条件(基底条件)を必ず設定します。
試験では、再帰を使った階乗の計算(5! = 5 × 4 × 3 × 2 × 1)などが出題されます。
4. 計算量(オーダー)の考え方
幽灯子/基本情報技術者副専門官アルゴリズムの良し悪しを測る指標の一つが計算量です。「データが増えたとき、処理にかかる時間がどのくらい増えるか」を表します。記号 O(オー) を使って表現します。
| 表記 | 意味 | イメージ |
|---|---|---|
| O(1) | 一定時間 | データ量に関係なく一瞬で終わる |
| O(n) | データ量に比例 | データが2倍になると時間も2倍 |
| O(n²) | データ量の2乗に比例 | データが2倍になると時間は4倍 |
| O(log n) | 対数的に増加 | データが2倍になっても時間は少ししか増えない |
たとえば、線形探索はO(n)、二分探索はO(log n)です。データが1,000件あるとき、線形探索は最大1,000回の比較が必要ですが、二分探索なら約10回で見つけられます。この差はデータが大きくなるほど劇的に広がります。
5. 試験対策のポイント

トレース(手作業での実行追跡)を練習しよう
試験では、フローチャートや擬似言語で書かれたアルゴリズムを読み、「変数の値がどう変化するか」を追いかける問題が多く出ます。これをトレースと呼びます。
練習のコツは以下のとおりです。
紙とペンを用意して、変数の値を表にしながら1ステップずつ追いかけることが最も効果的です。頭の中だけでやろうとすると、途中で混乱しやすくなります。最初は簡単な問題から始めて、慣れたら過去問に挑戦しましょう。間違えたら「どのステップで間違えたか」を確認し、同じパターンの問題をもう一度解くのがおすすめです。
擬似言語に慣れよう
FE試験では、特定のプログラミング言語ではなく擬似言語(試験独自の表記ルール)でアルゴリズムが出題されます。特別な文法を覚える必要はありませんが、試験の問題冊子に記載されている擬似言語の仕様は事前に確認しておきましょう。基本的な代入・比較・繰り返しの書き方さえ押さえれば、読み解くのは難しくありません。
おわりに
アルゴリズムは、最初は取っつきにくく感じるかもしれません。しかし、その本質は「問題を解く手順を整理すること」であり、日常生活でも無意識にやっていることの延長です。
まずは3つの基本構造(順次・選択・繰り返し)をしっかり理解し、代表的なアルゴリズム(探索・ソート)を身近な例と結びつけて覚えましょう。そしてトレースの練習を重ねれば、試験本番でも落ち着いて問題を解けるようになるはずです。
幽灯子/基本情報技術者副専門官一歩ずつ、着実に進んでいきましょう。応援しています。







コメント